Canopy Reading
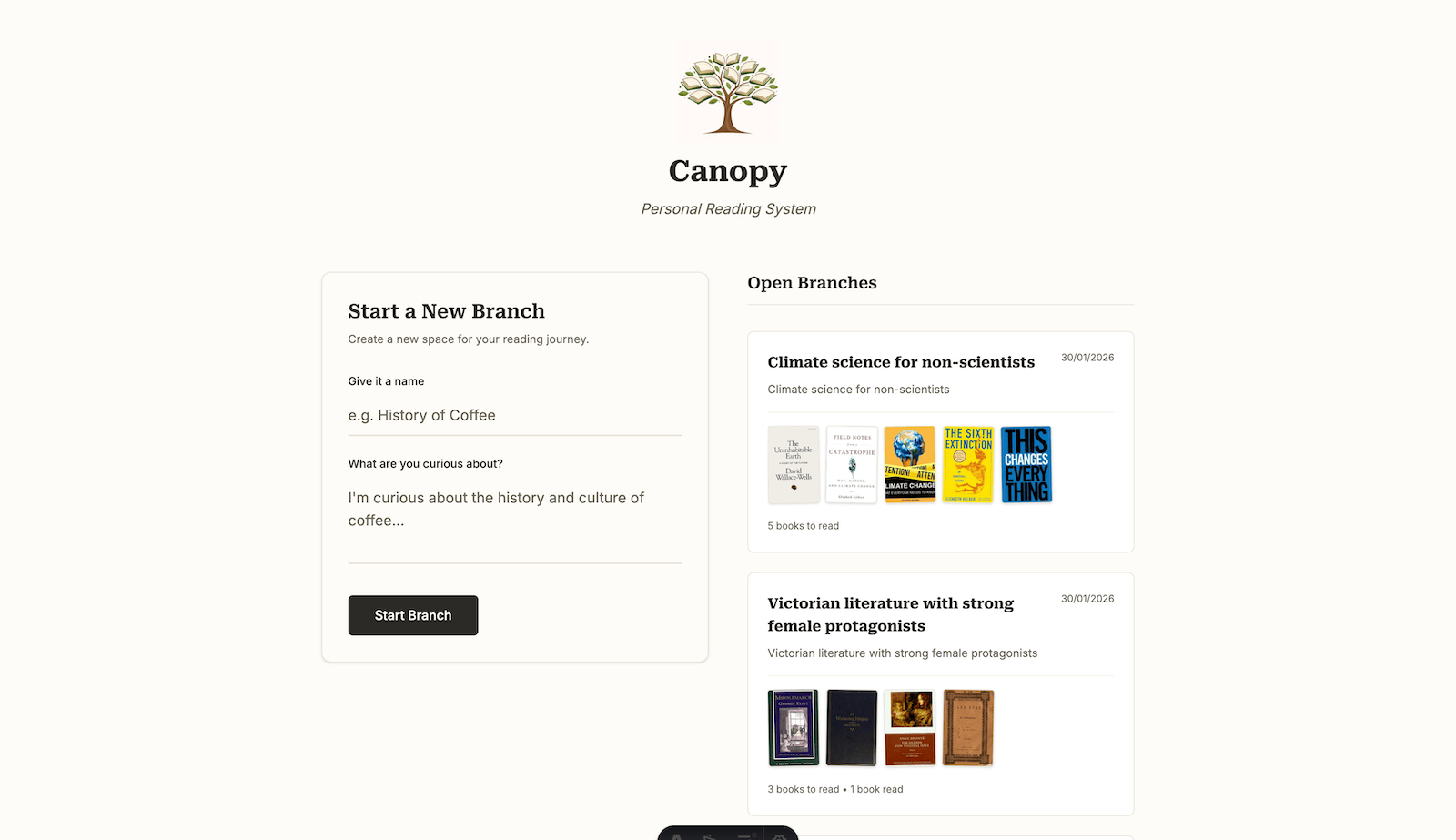
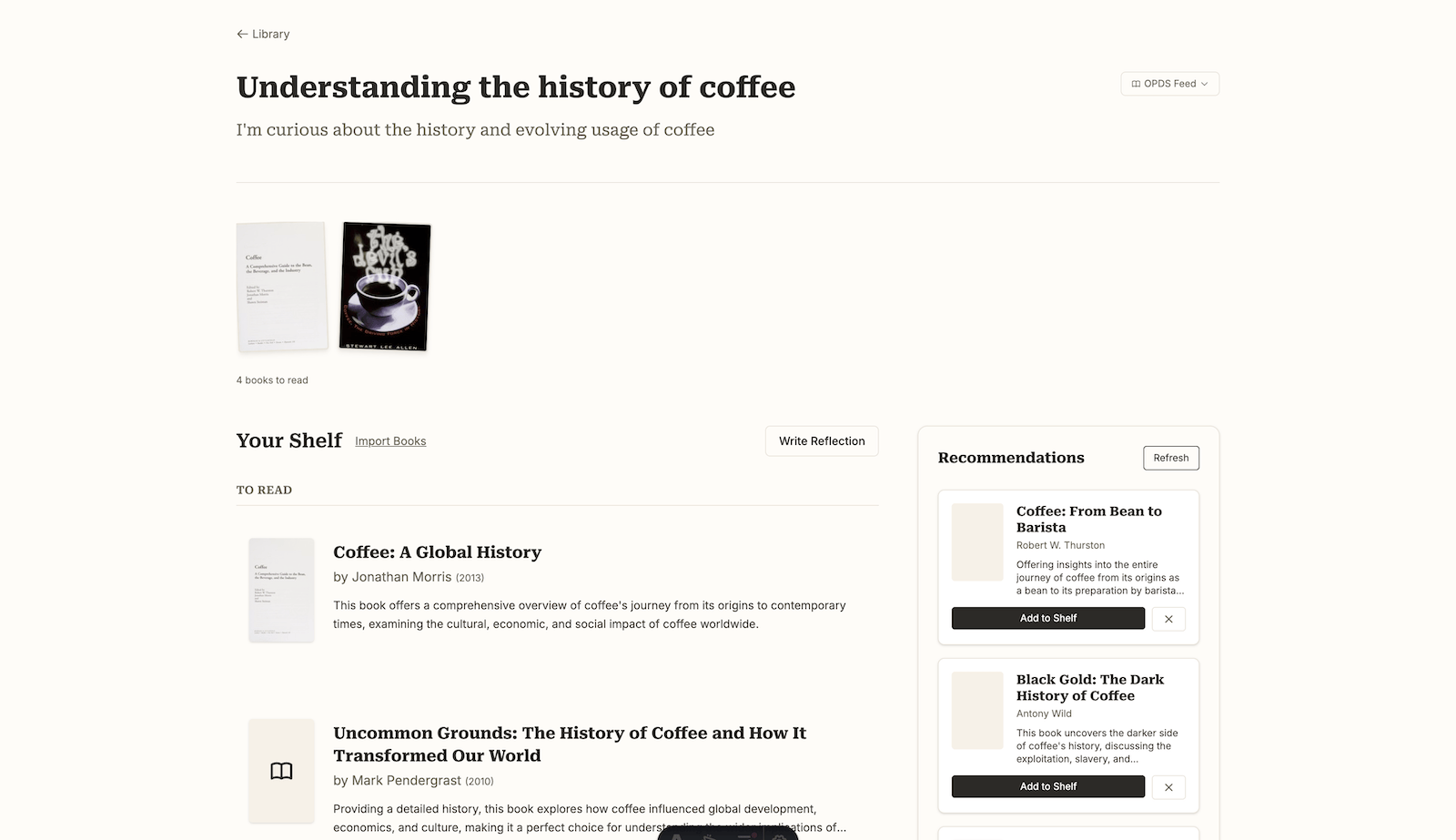
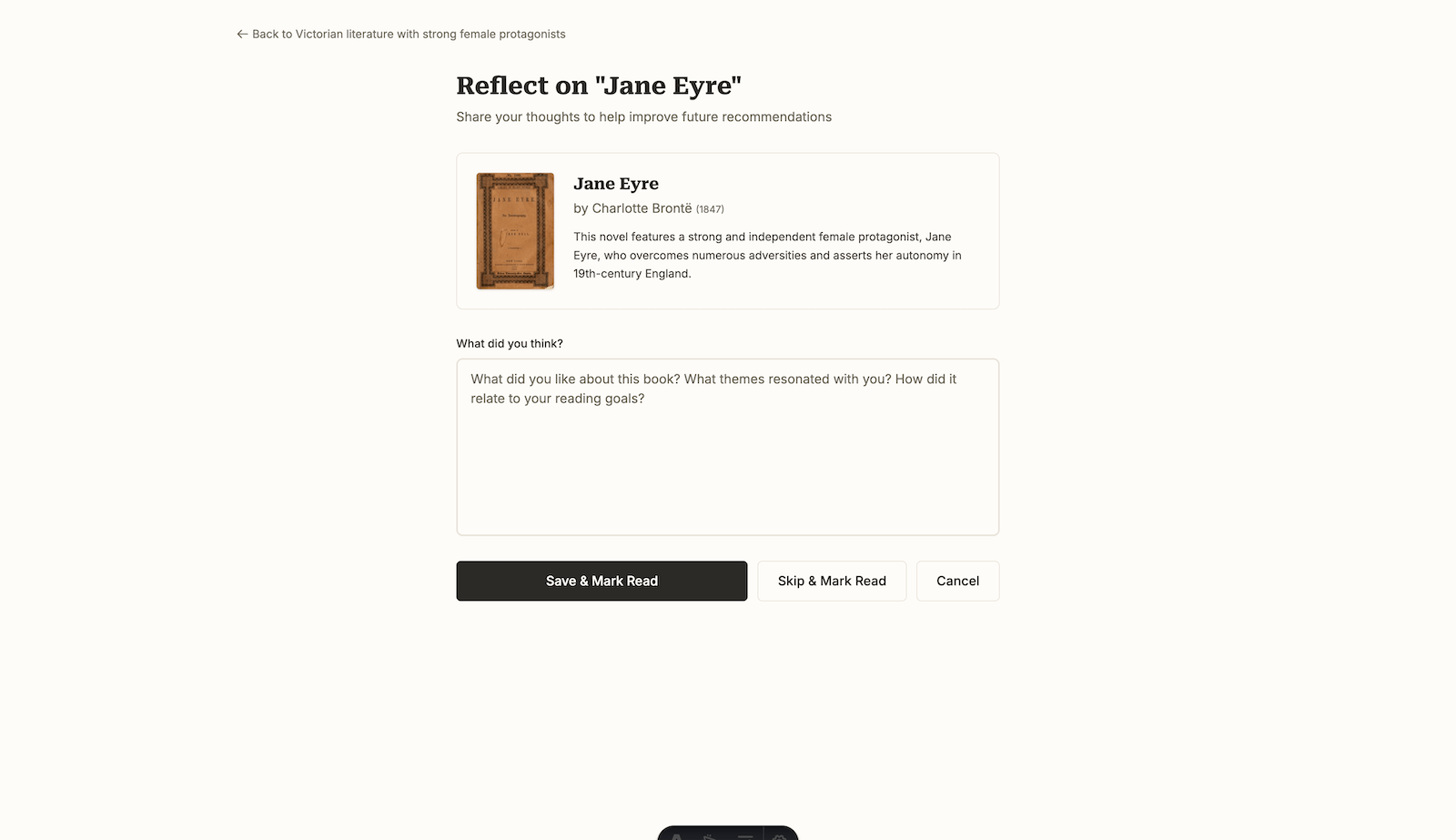
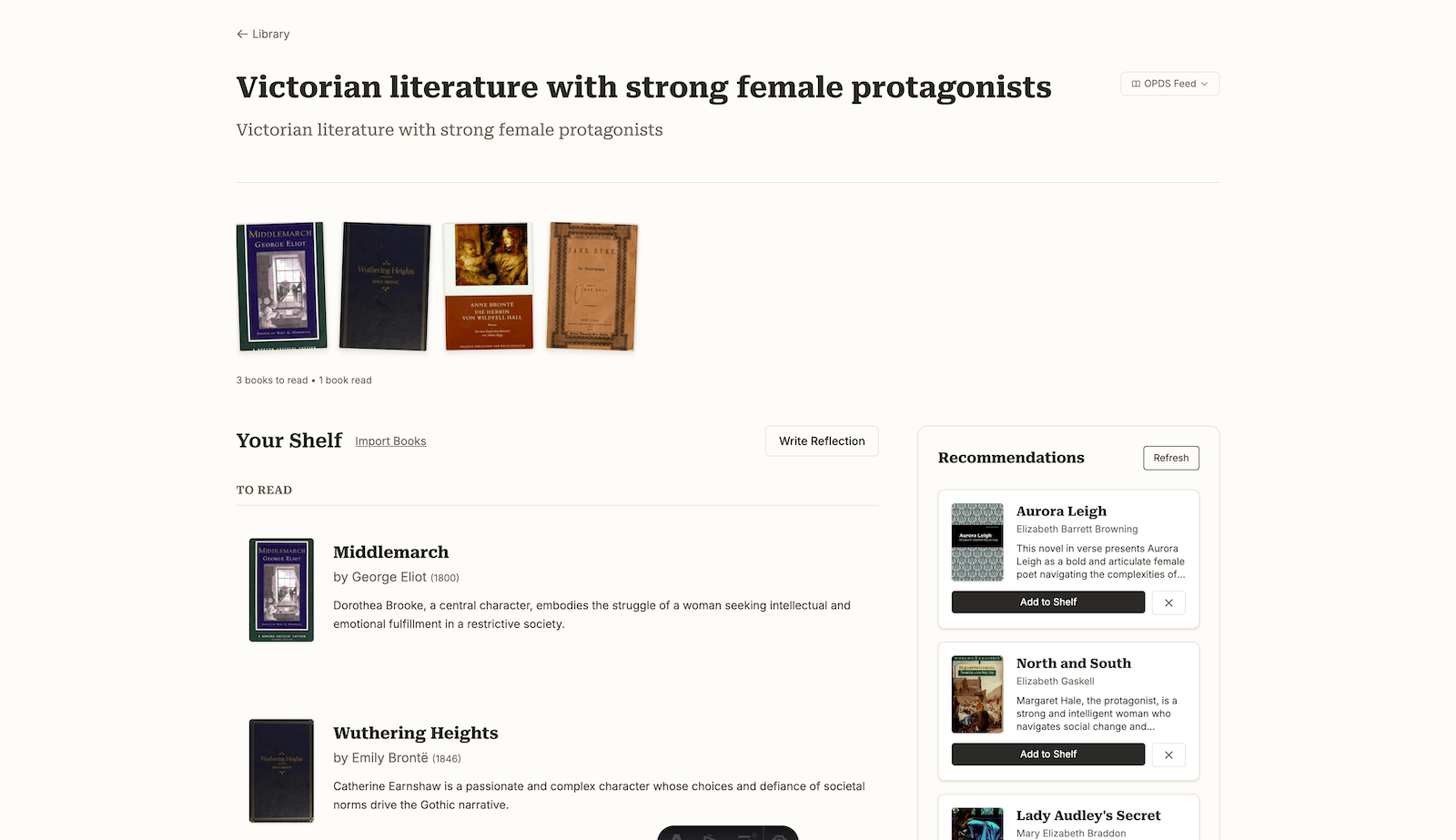
Canopy is a local-first, low-maintenance AI reading system that prioritizes reflection and long-term value over engagement metrics. Unlike traditional reading apps that provide generic recommendations based on your entire reading history, Canopy organizes reading around branches — themes, questions, or curiosities that guide what you read—and delivers recommendations that learn your preferences within each area of interest.
The system uses event sourcing to maintain an append-only log of all reading decisions, making every recommendation and reflection inspectable and reversible. Canopy integrates with e-reader apps via OPDS export, automatically enriches book metadata using OpenLibrary, and learns from user reflections to improve recommendations over time. It’s designed as personal software that works alongside platforms like Goodreads, focusing on specialized recommendation rather than social features.
Canopy Reading is available as a self-hostable web application that can be run locally or deployed to Cloudflare.
Find the source code on GitHub
Technology Stack
Framework:
- Astro with Server-Side Rendering (SSR)
- TypeScript
- Node.js filesystem adapter for standalone deployment
- Cloudflare Durable Objects adapter for storage
Frontend:
- Tailwind
- Astro components for UI
- Responsive design
Storage:
- Pluggable storage adapter architecture
- File-based event sourcing (default)
- Support for Cloudflare Durable Objects (via adapter)
- Human-readable JSON event files
AI & APIs:
- OpenAI GPT-4o for recommendation generation
- OpenLibrary API for book metadata enrichment
- Mock recommendation fallback for development
Data Formats:
- OPDS (Open Publication Distribution System) for e-reader integration
- Markdown for filesystem event storage and API responses (human-readable)
- JSON for Cloudflare Durable Objects event storage
Development Tools:
- Vitest for testing
- Biome for linting and formatting
- GitHub Actions for CI/CD
Architecture Patterns
Event Sourcing:
- All reading decisions stored as immutable events in chronological order
- Append-only log ensures complete history preservation
- State projection from event stream allows for time-travel debugging
Storage Adapter Pattern:
- Pluggable storage backends (filesystem, Cloudflare Durable Objects, memory)
- Clean interface abstraction (
StorageAdapter) for different deployment targets - Factory pattern for adapter instantiation based on environment configuration
Projection Pattern:
- Branch state computed from event stream rather than stored directly
- Inbox and library derived from events, ensuring consistency
- Context window built from history for AI recommendations
Branch-Based Organization:
- Each branch maintains independent recommendation context
- Category-specific learning prevents preference bleeding across genres
- Fork capability allows branching reading paths from existing branches
API-First Design:
- RESTful API endpoints for all operations
- OPDS-compatible export endpoints for e-reader integration
- Stateless API design with event sourcing providing persistence
Reflection-Driven Learning:
- User reflections inform future recommendations within each branch
- Book-level and branch-level reflections both contribute to context
- AI recommendations improve as reflection history grows
Challenges Faced
Storage Adapter Abstraction:
- Creating a unified interface that works for both file system and Cloudflare Durable Objects
- Handling different consistency models (file system vs. distributed storage)
- Maintaining adapter compatibility while adding new features
AI Context Management:
- Building effective context windows from event history for recommendations
- Balancing context size with API token limits
- Extracting meaningful signals from user actions (accept/reject/defer) and reflections
Local-First Philosophy:
- Ensuring all data remains accessible without cloud dependencies
- File-based storage that’s git-friendly and human-readable
- No database migrations or complex infrastructure requirements
Long-Lived Personal Software:
- Creating software that can be maintained over years without significant ongoing effort
- Minimizing dependencies to reduce security updates and breaking changes
- Ensuring file storage is useful in isolation—all event files are human-readable markdown that can be understood and processed without the application
- Designing for “pick up and put down” usage patterns where the software remains functional after months of inactivity